Overview
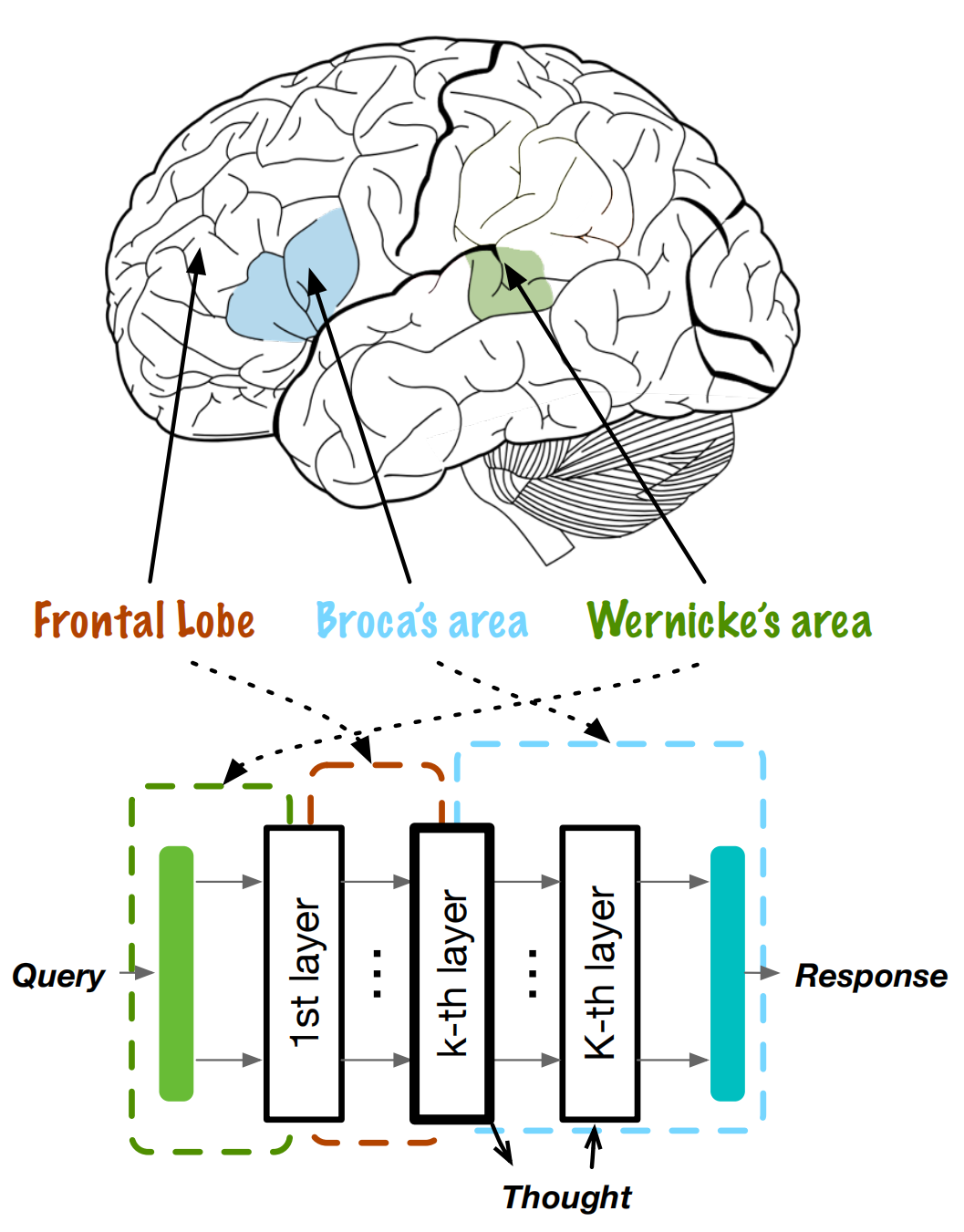
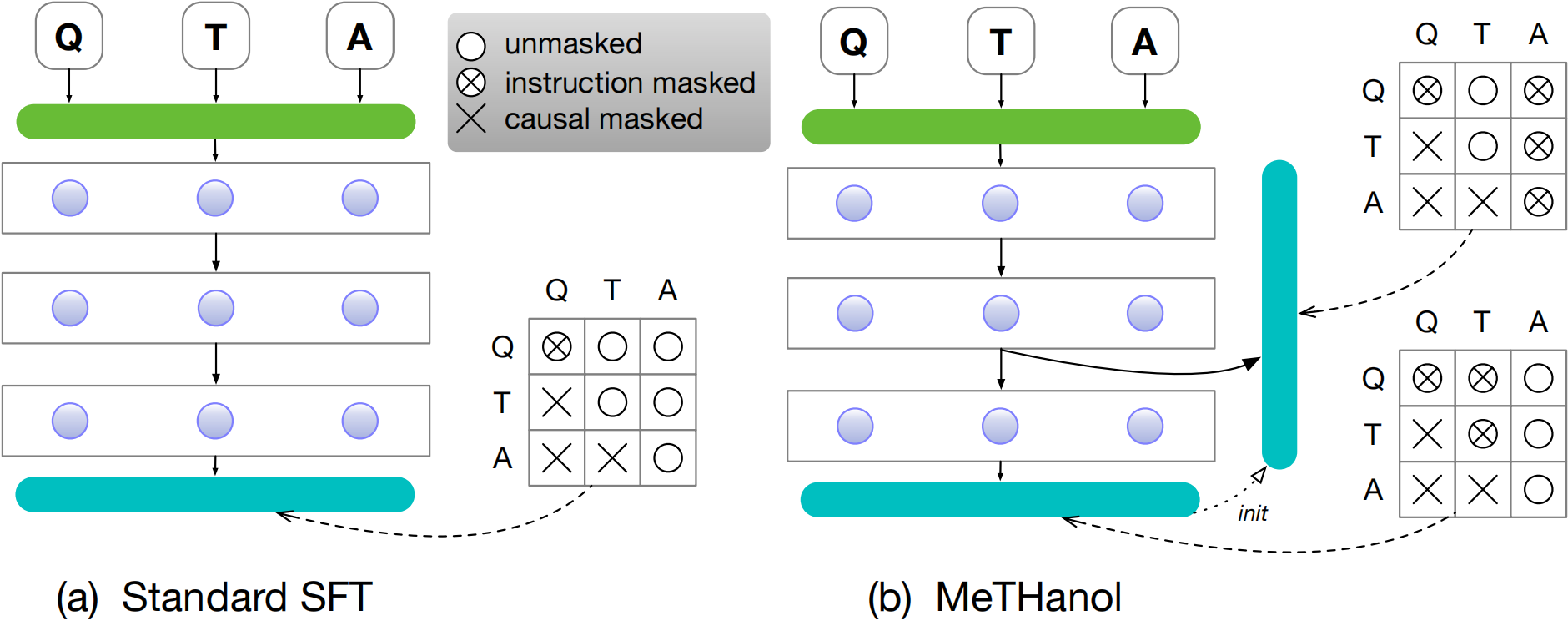
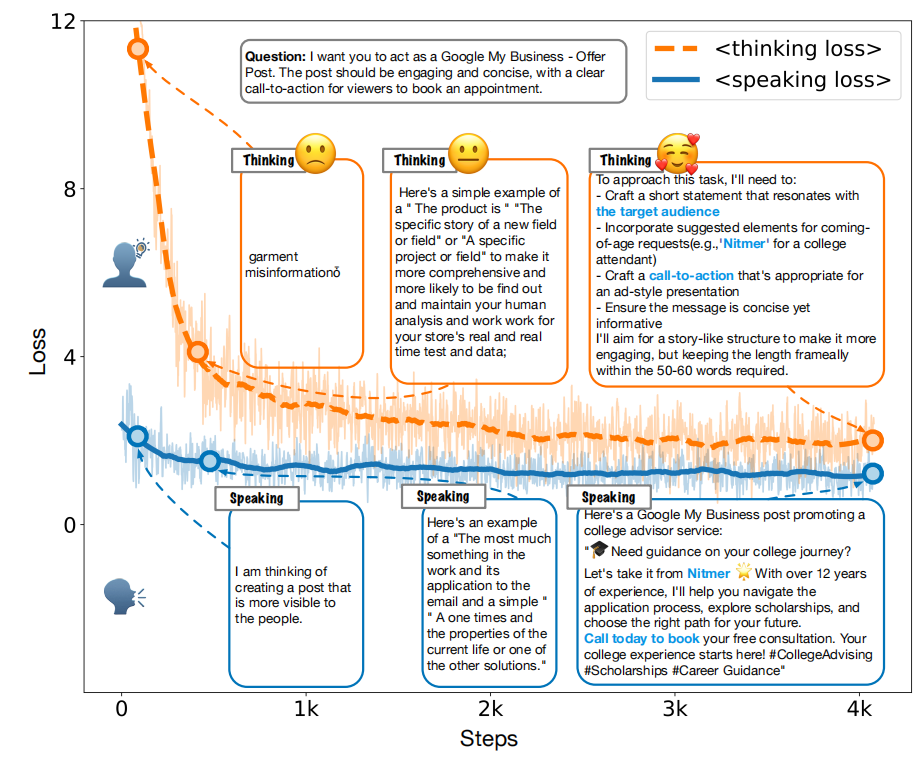
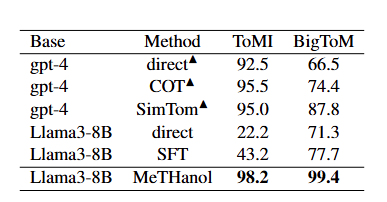
Current research efforts are focused on enhancing the thinking and reasoning capability of large language models (LLMs) by prompting, data-driven emergence and inference-time computation. In this study, we consider stimulating language models' thinking and cognitive abilities from a modular perspective, which mimics the human brain architecture. We select a specific intermediate attention layer with newly implemented language heads. We conduct dual-layer fine-tuning by annotated (query, thought, response) samples and show that the intermediate layer can also learn to decode fluent and reasonable language tokens. A two-pass inference mechanism is designed to generate thoughts then formal responses. The entire framework is called modularized thinking language model (MeTHanol) which can enhance LLM's cognitive behaviors as indicated by Theory of Mind (ToM) and Vignette-based experiments. Case studies also show that MeTHanol can plan and self-reflect and generate human-like thoughts and answers, even on unseen and open-domain tasks. MeTHanol can also adapt to a personalized prompt and behave as the specified character. Our study holds promise for significant cognitive gains from a modular perspective.

@INPROCEEDINGS{11229297,
author={Xi, Ningyuan and Wang, Xiaoyu and Wu, Yetao and Chen, Teng and Gu, Qingqing and Ji, Luo},
booktitle={2025 International Joint Conference on Neural Networks (IJCNN)},
title={MeTHanol: Modularized Thinking Language Models with Intermediate Layer Thinking, Decoding and Bootstrapping Reasoning},
year={2025},
volume={},
number={},
pages={1-9},
keywords={Training;Adaptation models;Inference mechanisms;Large language models;MIMICs;Computer architecture;Oral communication;Cognition;Decoding;Methanol;modularity;LLM;latent space;reasoning},
doi={10.1109/IJCNN64981.2025.11229297}}